


TF-IDF adalah metode statistik yang umum digunakan dalam pengambilan informasi dan pemrosesan bahasa alami.
Ini adalah konsep penting untuk memahami bagaimana mesin pencari menganalisis konten web dan mengidentifikasi istilah-istilah kunci yang dapat dikaitkan dengan permintaan pencarian.
Inilah yang perlu Anda ketahui tentangnya.
Apa Frekuensi Dokumen Invers Frekuensi Term (TF-IDF)?
Frekuensi dokumen invers frekuensi istilah (TF-IDF) mengukur pentingnya sebuah kata untuk dokumen tertentu.
Ini adalah produk dari dua statistik: frekuensi term (TF) dan frekuensi dokumen terbalik (IDF) .
Frekuensi Jangka (TF)
Frekuensi istilah (TF) dapat didefinisikan sebagai frekuensi relatif suatu istilah (t) dalam suatu dokumen (d).
Ini dihitung dengan membagi berapa kali istilah tersebut muncul dalam dokumen ( f t , d ) dengan jumlah total istilah dalam dokumen.
Berikut rumusnya:
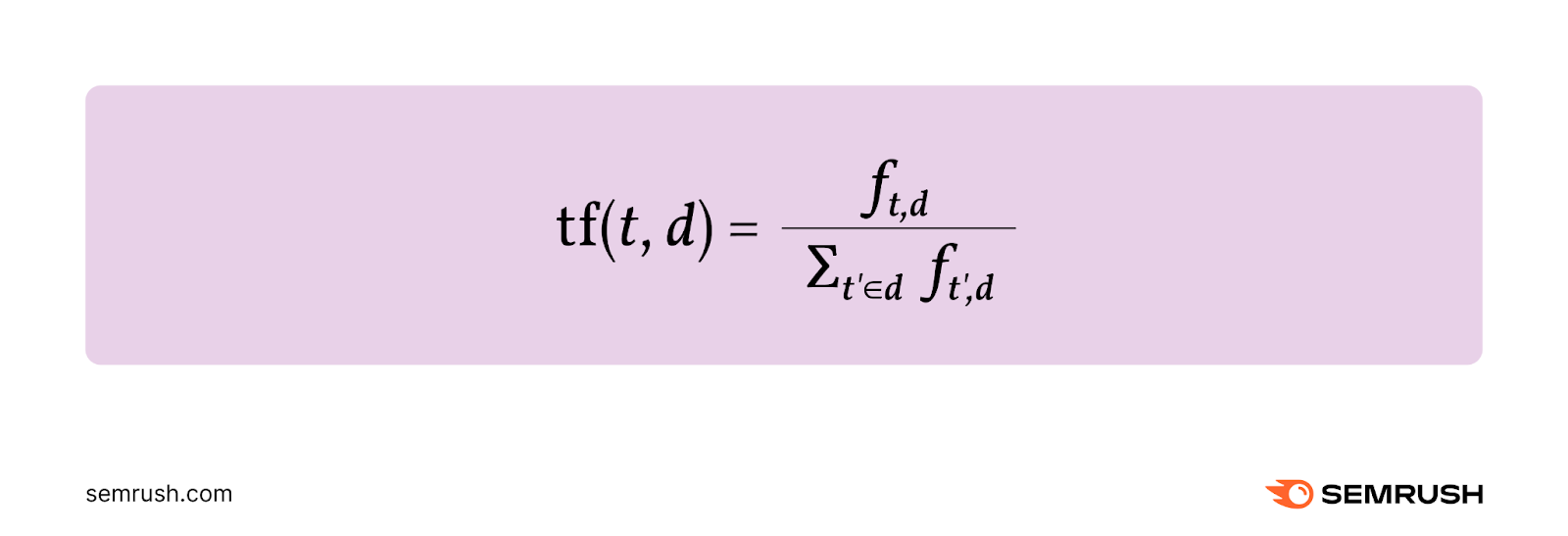

Misalnya, Anda memiliki dokumen yang berisi 10.000 istilah. Dan istilah tertentu muncul sebanyak 25 kali dalam dokumen.
Anda akan menghitung frekuensi istilah sebagai berikut:
TF = 25/10.000 = 0,0025
Frekuensi Dokumen Terbalik (IDF)
Frekuensi dokumen terbalik (IDF) mengukur jumlah informasi yang diberikan suatu istilah.
Dihitung dengan membagi jumlah dokumen (N) dengan jumlah dokumen yang memuat istilah tersebut. Kemudian, ambil logaritma dari hasil bagi itu.
Berikut rumusnya:
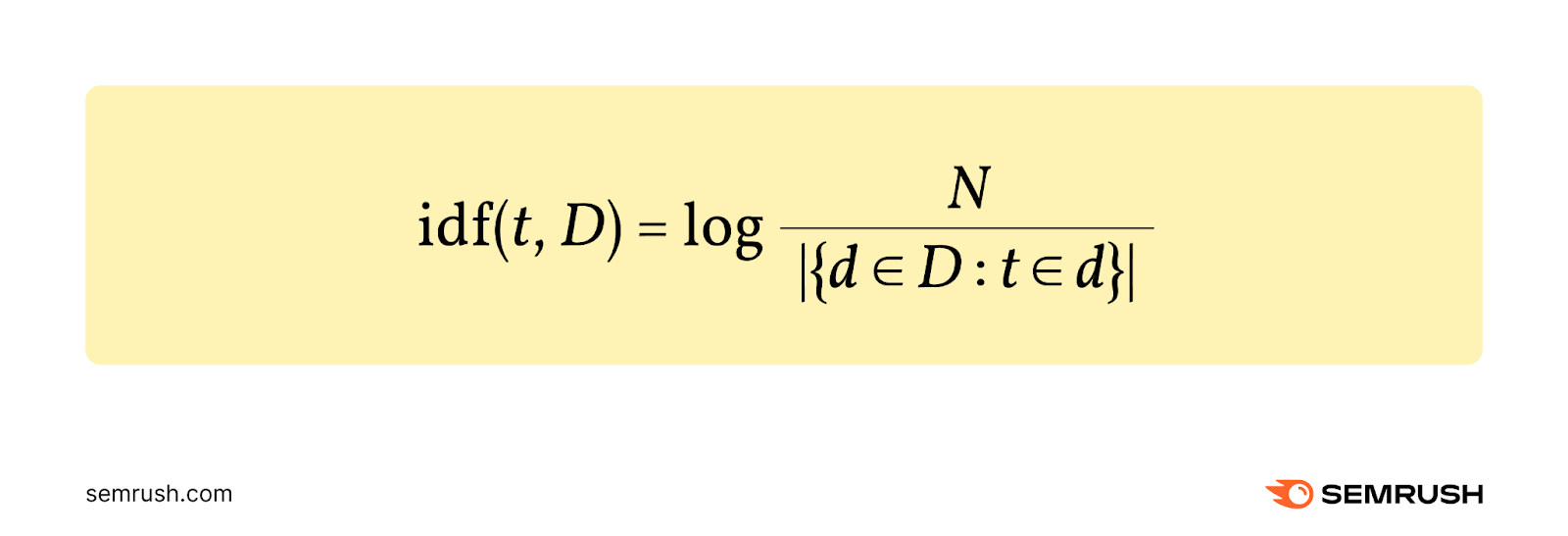
Katakanlah Anda memiliki koleksi 10.000 dokumen (N=10.000), dan sebuah istilah muncul di 500 dokumen tersebut.
Inilah cara Anda menghitung IDF:
IDF = log 10.000/500 = 1,30
Rumus TF-IDF
Untuk menghitung TF-IDF, kita perlu mengalikan nilai TF dan IDF:

TF-IDF = 0,00325
Skor akhir menunjukkan relevansi istilah tersebut, dengan skor yang lebih tinggi menunjukkan relevansi yang lebih tinggi dan skor yang lebih rendah menunjukkan relevansi yang lebih rendah.
Contoh Cara Menghitung TF-IDF
Jadi, bagaimana cara kerja TF-IDF dalam praktiknya?
Mempelajari rumus TF, IDF, dan TF-IDF saja bisa membuat Anda kewalahan. Mari kita lihat contoh nyata.
Katakanlah istilah “mobil” muncul 25 kali dalam dokumen yang berisi 1.000 kata.
Kami akan menghitung frekuensi istilah (TF) sebagai berikut:
TF = 25/1.000 = 0,025
Selanjutnya, misalkan kumpulan dokumen terkait berisi total 15.000 dokumen.
Jika 300 dari 15.000 dokumen mengandung istilah “mobil”, kita akan menghitung kebalikan frekuensi dokumen sebagai berikut:
IDF = log 15.000/300 = 1,69
Sekarang kita bisa menghitung skor TF-IDF dengan mengalikan dua angka berikut:
TF-IDF = TF x IDF = 0,025 x 1,69 = 0,04225
Cara Menggunakan TF-IDF
TF-IDF memiliki sejumlah aplikasi. Ini dapat digunakan sebagai faktor pembobotan untuk:
- Pengambilan informasi : Variasi TF-IDF digunakan sebagai faktor pembobotan oleh mesin pencari untuk membantu memahami relevansi suatu halaman dengan permintaan pencarian pengguna
- Penambangan teks : TF-IDF dapat membantu mengukur isi dokumen, yang merupakan pertanyaan sentral dalam penambangan teks
- Pemodelan pengguna : Penerapan TF-IDF lainnya melibatkan bantuan dalam pembuatan model perilaku dan minat pengguna, yang kemudian dapat digunakan oleh mesin rekomendasi produk dan konten
Gunakan Pemeriksa SEO On Page Semrush untuk TF-IDF
Ingin melakukan sedikit analisis TF-IDF untuk situs web Anda sendiri? Di sinilah Pemeriksa SEO On Page Semrush dapat membantu.
Anda dapat menggunakannya untuk membandingkan skor TF-IDF antara konten situs web Anda dan halaman pesaing.
Begini caranya:
Masukkan domain Anda pada halaman On Page SEO Checker dan tekan tombol “ Dapatkan ide ”.
Alat tersebut kemudian akan menganalisis situs web Anda. Dan memberi Anda laporan yang berisi daftar ide untuk mengoptimalkan situs web Anda untuk mesin pencari.
Untuk melihat skor TF-IDF pada halaman tertentu, kunjungi tab “ Ide Pengoptimalan ”.
Temukan halaman yang Anda inginkan dalam daftar, dan klik tombol biru yang menunjukkan jumlah total ide untuk halaman tersebut.
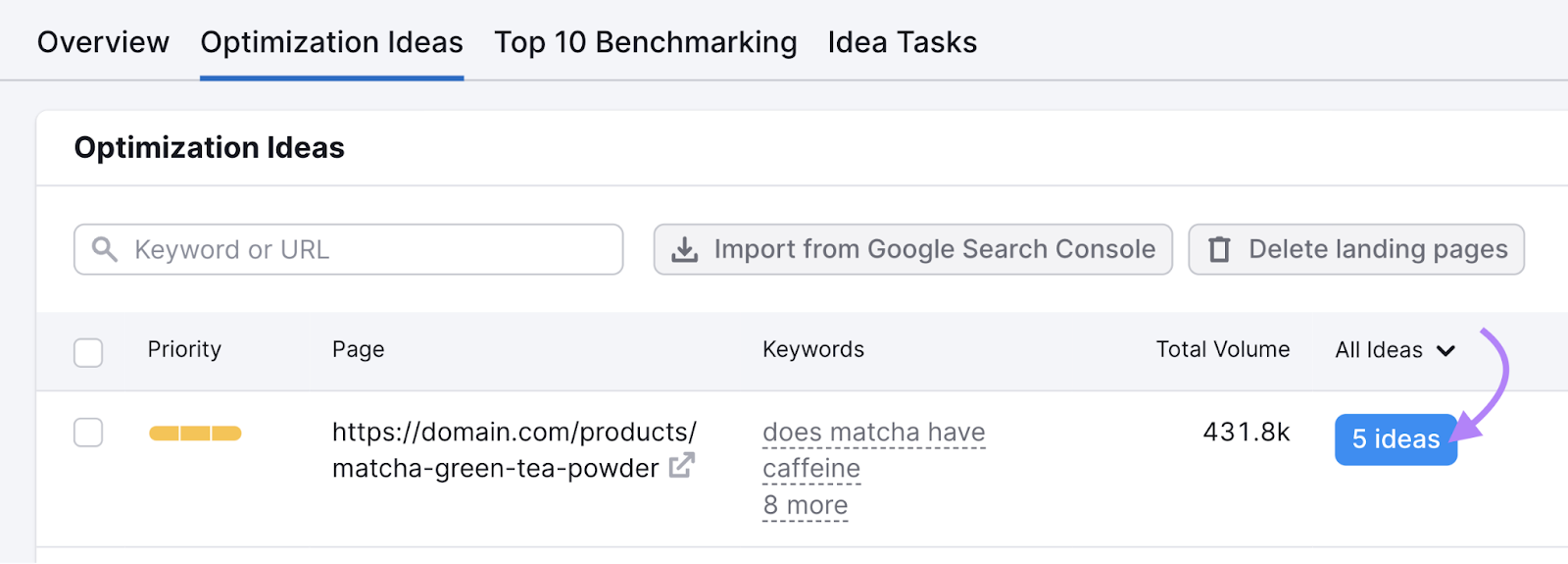
Di sini, Anda akan disajikan daftar ide untuk halaman spesifik tersebut.
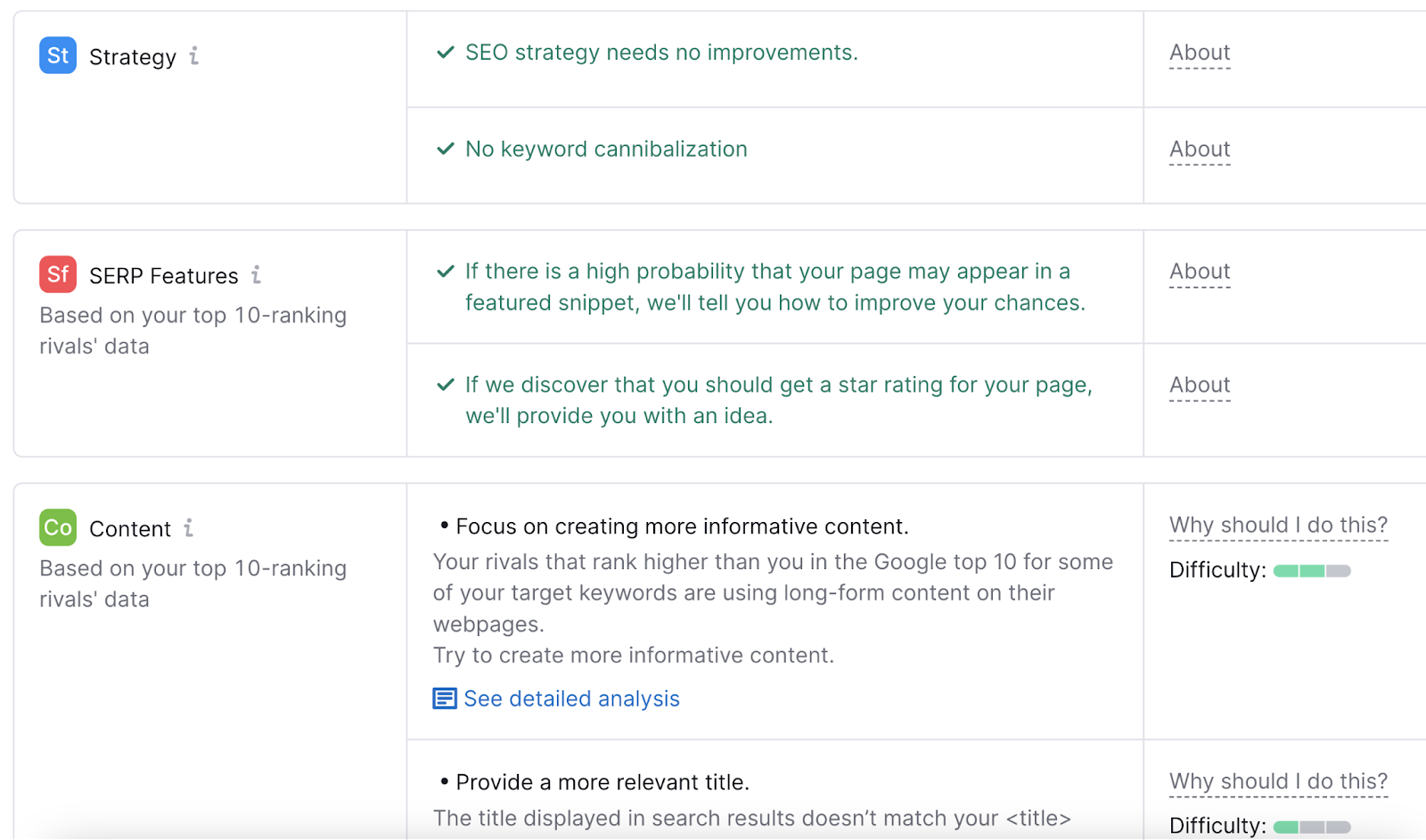
Klik tautan “ Lihat analisis terperinci ” di bawah salah satu gagasan yang tercantum dalam laporan.
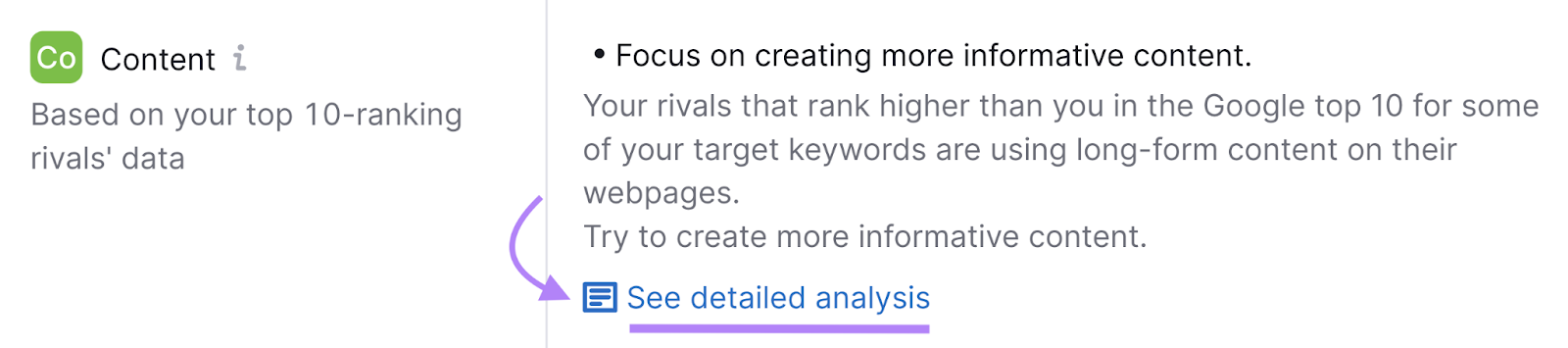
Buka tab “ Penggunaan Kata Kunci ”.
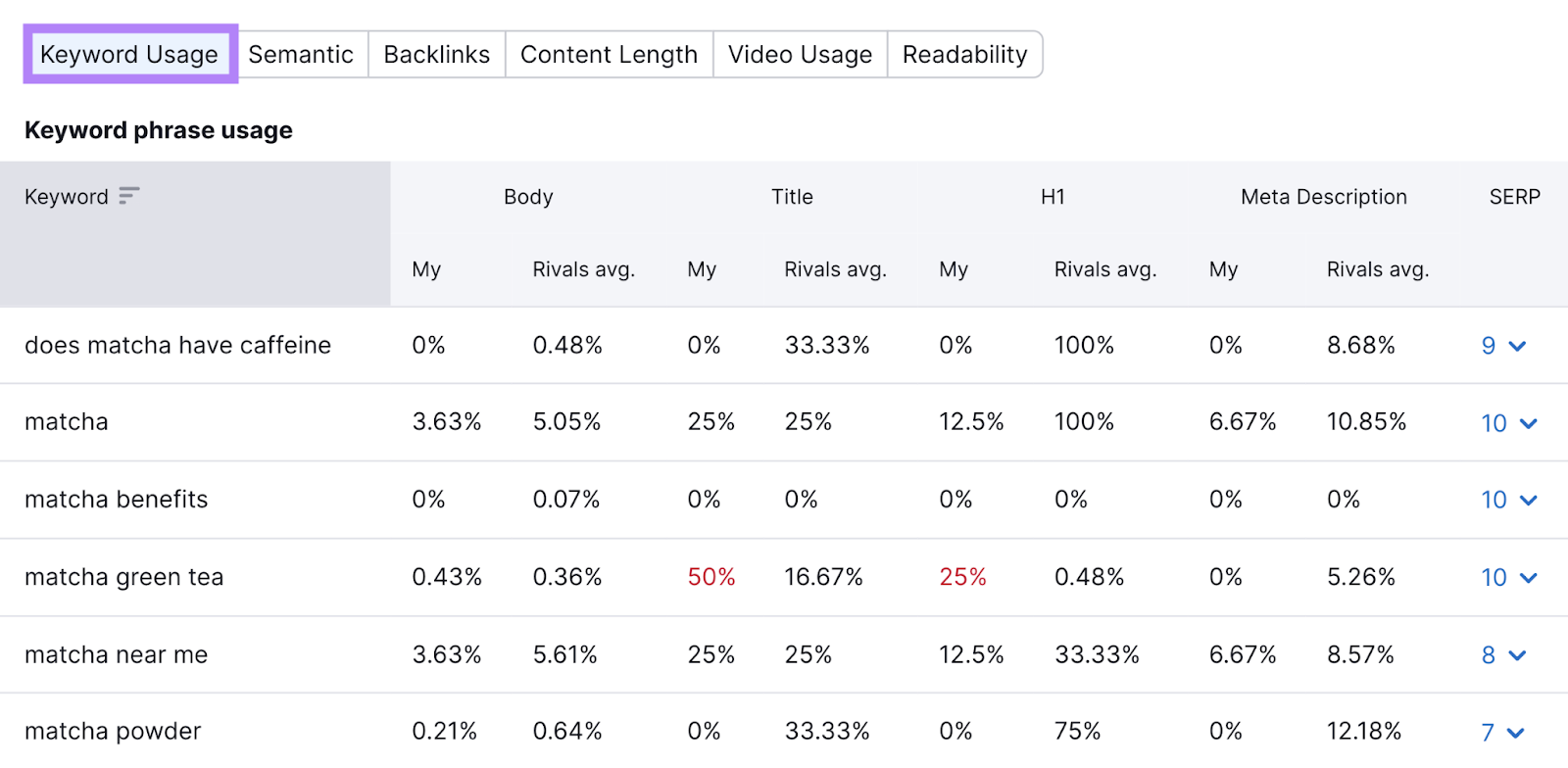
Anda dapat membandingkan skor TF-IDF di bagian “TF-IDF”, seperti yang ditunjukkan di bawah ini.
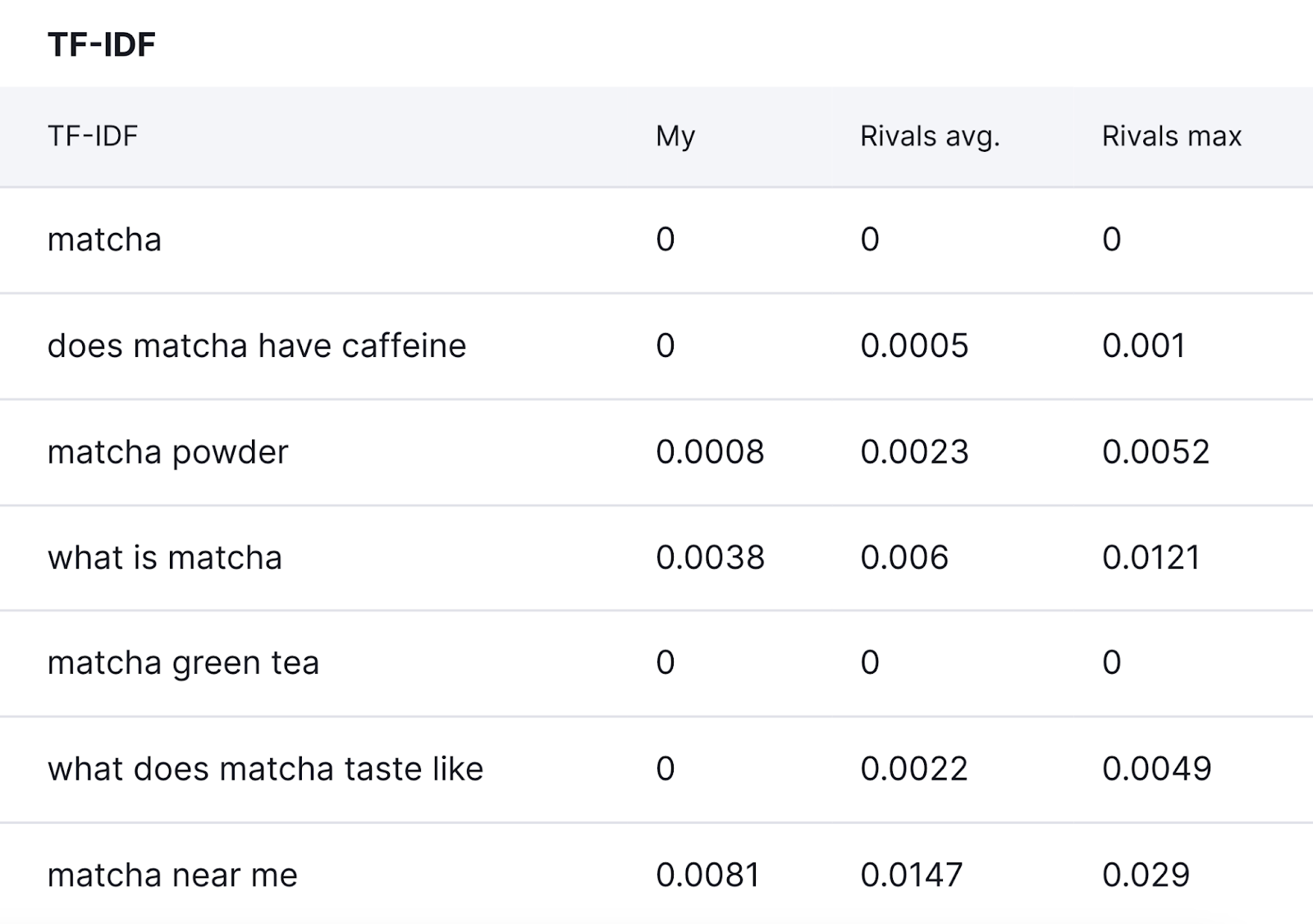

Manfaat Menggunakan TF-IDF
Berikut keunggulan utama TF-IDF:
- Mudah dihitung : Mungkin manfaat terbesar menggunakan TF-IDF adalah perhitungannya cukup sederhana dan dapat berfungsi sebagai titik awal untuk analisis lebih lanjut
- Mengidentifikasi istilah-istilah penting : Ini dapat membantu mengidentifikasi istilah-istilah penting dalam sebuah dokumen, yang sangat berguna untuk memahami isi dokumen
- Membedakan antara istilah umum dan istilah langka : Karena TF-IDF melihat jumlah kemunculan suatu istilah dalam satu dokumen—dan juga jumlah kemunculan istilah yang sama dalam kumpulan dokumen—hal ini membantu membedakan antara istilah umum dan istilah langka. istilah langka
- Tidak bergantung pada bahasa : TF-IDF berfungsi di semua bahasa dan tidak dibatasi oleh bahasa dokumen
- Scalable : Mampu menangani kumpulan data sangat besar yang berisi dokumen dalam jumlah besar
Kekurangan Menggunakan TF-IDF
TF-IDF juga hadir dengan serangkaian keterbatasannya:
- Istilah yang sangat jarang bisa menjadi masalah : Skor IDF bisa sangat tinggi untuk istilah yang sangat jarang, sehingga membuat istilah tersebut tampak lebih penting daripada yang sebenarnya
- Tidak memahami makna atau konteks : TF-IDF hanya mengukur frekuensi istilah—tidak memahami makna di balik istilah atau konteks penggunaannya
- Mengabaikan urutan kata : TF-IDF tidak peduli dengan urutan kata sehingga tidak dapat memahami kata benda atau frasa majemuk sebagai istilah satuan tunggal
- Kesulitan menafsirkan sinonim dan kata-kata serupa : Karena TF-IDF memperlakukan setiap istilah secara independen, TF-IDF mungkin mengalami kesulitan mengenali sinonim dan kata-kata serupa, yang dapat menyebabkan skor menyesatkan
Peran TF-IDF yang Berkembang dalam AI dan Pembelajaran Mesin
TF-IDF memiliki banyak aplikasi untuk kecerdasan buatan (AI) dan algoritma pembelajaran mesin, termasuk pengambilan informasi, penambangan teks, dan banyak lagi.
Teknologi ini terus berkembang seiring dengan AI, dengan model TF-IDF khusus domain yang sedang dikembangkan saat ini. Model-model ini mempertimbangkan karakteristik dan nuansa industri tertentu yang menjadi tujuan model tersebut.
Beberapa contohnya termasuk model TF-IDF yang ditujukan untuk industri perawatan kesehatan, yang mampu menganalisis catatan klinis dan rekam medis guna mendapatkan informasi berharga untuk mendiagnosis dan mengobati penyakit.
TF-IDF kini dikombinasikan dengan model pembelajaran mesin transformator (yang mempelajari konteks dengan melacak hubungan antar istilah).
Ini juga digunakan bersama dengan penyematan kata. Dalam pendekatan ini, istilah dipetakan ke vektor, dan hubungan di antara istilah tersebut ditentukan berdasarkan jarak dalam ruang vektor.
Dengan kata lain, metode ini meningkatkan analisis teks dan pengambilan informasi.
Tetap di Atas TF-IDF dengan SEMrush
Anda dapat tetap mengetahui skor TF-IDF konten Anda dan membandingkannya dengan pesaing Anda dengan menggunakan Pemeriksa SEO On Page Semrush .
Selain menampilkan skor TF-IDF, On Page SEO Checker juga dapat membantu Anda mengidentifikasi puluhan cara untuk meningkatkan SEO on-page website Anda .
Dan tingkatkan kemungkinan Anda untuk memberi peringkat konten Anda lebih tinggi di hasil mesin pencari.




0 Comments